






























Microsoft ka publikuar një artikull në blogun e tij të sigurisë për të shpjeguar se si zbulon dhe bllokon sulmet kundër modeleve gjeneruese të inteligjencës artificiale. Kompania Redmond përdor metoda të ndryshme për të shmangur manipulimin e LLM (Large Language Model) përmes kërkesave (inputeve) të përdorura për të anashkaluar mbrojtjen e zbatuar. Mjete specifike do të jenë të disponueshme për zhvilluesit në Azure AI Studio.
Si Microsoft zbulon dhe zbut sulmet
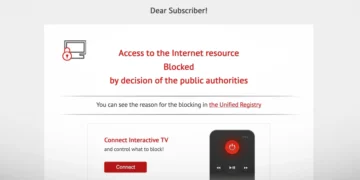
Microsoft thekson se sistemet e tij të AI janë të dizajnuara me shtresa të ndryshme mbrojtëse për të parandaluar abuzimin e modeleve. Megjithatë, aktorët e këqij përpiqen t’i anashkalojnë këto mbrojtje për të marrë rezultate të paautorizuara (jailbreaks), të tilla si udhëzime për të kryer aktivitete të paligjshme.
Manipulimi i modelit të AI duke përdorur inpute që anashkalojnë mbrojtjen quhet injeksion direkt i shpejtë. Kur ju kërkohet të përpunoni një dokument të krijuar nga një palë e tretë me synimin për të shfrytëzuar një dobësi në model, kjo quhet injeksion indirekt i shpejtë.
Ky lloj i fundit i sulmit është më i rrezikshëm. Për shembull, mund t’i kërkoni modelit të përmbledhë një email me një ngarkesë që kërkon të dhëna të ndjeshme të përdoruesit dhe i dërgon në një server të largët. Microsoft ka zhvilluar një teknikë, të quajtur Spotlighting, që i mban udhëzimet e modelit të ndara nga të dhënat e jashtme, duke minimizuar shanset që një sulm indirekt i menjëhershëm të ketë sukses.
Kompania Redmond ka zhvilluar gjithashtu një teknikë për të zbutur efektet e një lloji të ri jailbreak, të njohur si Crescendo. Në këtë rast, modeli mashtrohet duke shfrytëzuar përgjigjet e modelit. Në vend të hyrjes së parë, rezultati i dëshiruar merret në rreth 10 përsëritje (pyetje/përgjigje).
Microsoft përditësoi Copilot për të zbutur ndikimin e Crescendo. Filtrat marrin parasysh të gjithë bisedën dhe sistemet janë trajnuar për të zbuluar këtë lloj jailbreak.














{kind=link}
Discussion about this post